Agentica
https://github.com/wrtnlabs/agentica
The simplest Agentic AI framework, specialized in LLM Function Calling.
With @agentica, you can build Agentic AI chatbot only with Swagger document built by @nestia/sdk. Complex agent workflows and graphs required in conventional AI agent development are not necessary in @agentica. Only with the Swagger document, @agentica will do everything with the function calling.
Look at below demonstration, and feel how @agentica is powerful. Now, you can let users to search and purchase products only with conversation texts. The backend API functions would be adequately called in the AI chatbot with LLM function calling.
@nestia/agent had been migrated to @agentica/* for enhancements and separation to multiple packages extending the functionalities.
import { Agentica } from "@agentica/core";
import typia from "typia";
const agent = new Agentica({
controllers: [
await fetch(
"https://shopping-be.wrtn.ai/editor/swagger.json",
).then(r => r.json()),
typia.llm.application<ShoppingCounselor>(),
typia.llm.application<ShoppingPolicy>(),
typia.llm.application<ShoppingSearchRag>(),
],
});
await agent.conversate("I wanna buy MacBook Pro");- Shopping A.I. Chatbot Application: https://nestia.io/chat/shopping
- Shopping Backend Repository: https://github.com/samchon/shopping-backend
- Shopping Swagger Document (
@nestia/editor): https://nestia.io/editor/?url=…
Playground
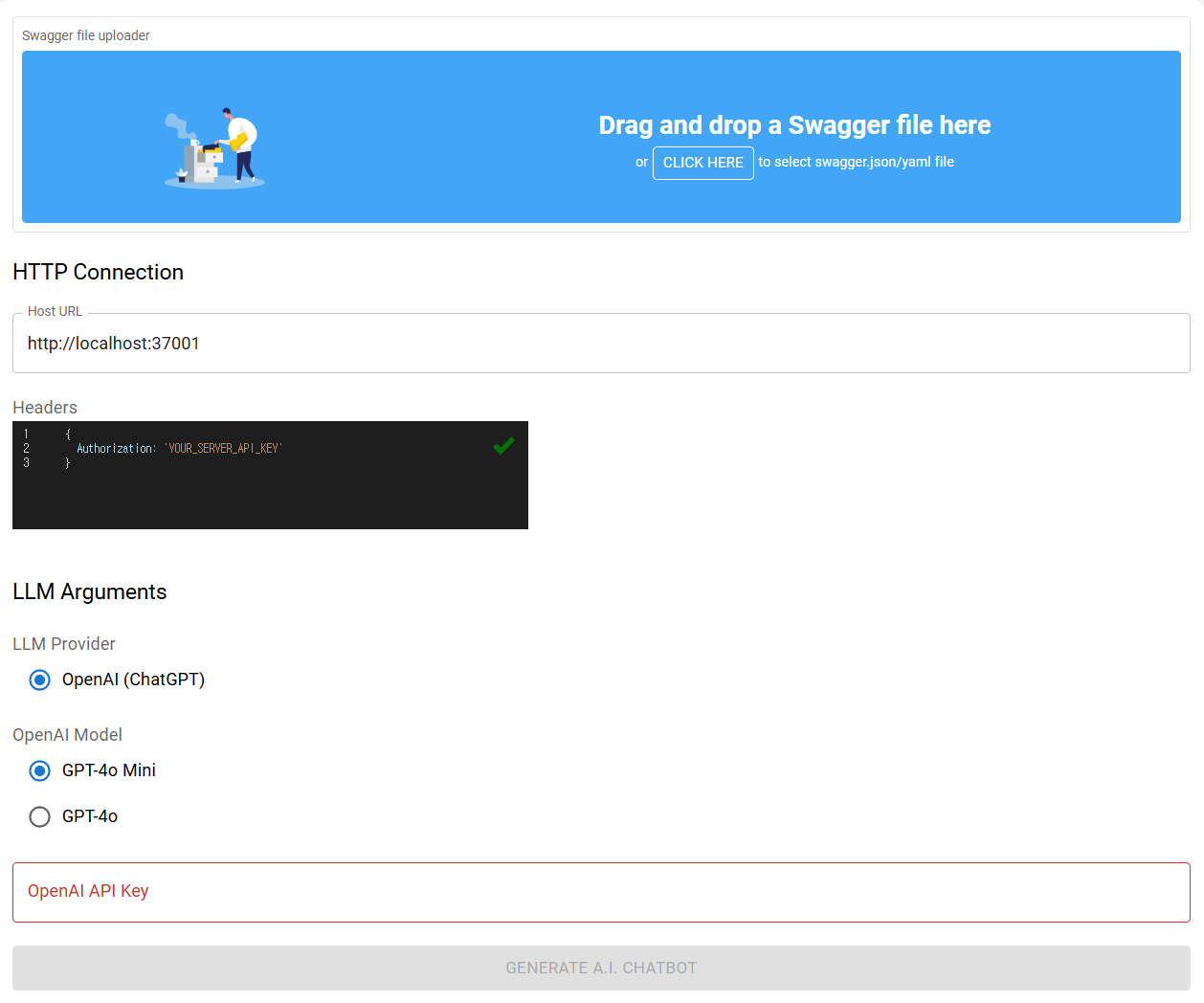
You can test your backend server’s A.I. chatbot with the following playground.
Upload your Swagger document file to the playground website, and start conversation with your backend server. If your backend server’s documentation is well written so that the A.I. chatbot quality is satisfiable, you can start your own A.I. chatbot development with @agentica.
Backend Development
Setup
npm install @agentica/core @agentica/rpc @samchon/openapi tgridInstall above packages on your NestJS project.
The first package @agentica/core is the core package of @agentica framework. It provides Agentic AI that is based on the LLM function calling. And @agentica/rpc is the package for the WebSocket RPC (Remote Procedure Call) combining with TGrid.
The last package @samchon/openapi is a library for converting OpenAPI document to LLM functioni calling schema.
Bootstrap
const app: INestApplication = await NestFactory.create(AppModule);
await WebSocketAdaptor.upgrade(app);Call WebSocketAdaptor.upgrade() function to the NestJS application instance.
It will upgrade the NestJS backend server to be compatible with WebSocet protocol.
API Controller
import { AgenticaRpcService, IAgenticaRpcListener } from "@agentica/rpc";
import { WebSocketRoute } from "@nestia/core";
import { Controller } from "@nestjs/common";
import { WebSocketAcceptor } from "tgrid";
@Controller("chat")
export class ChatController {
@WebSocketRoute()
public async start(
@WebSocketRoute.Acceptor()
acceptor: WebSocketAcceptor<
null, // header
AgenticaRpcService,
IAgenticaRpcListener
>,
): Promise<void> {
const agent = new Agentica({ ... })
await acceptor.accept(
new AgenticaRpcService({
agent,
listener: acceptor.getDriver(),
}),
);
}
}At last, define a WebSocket route to a specific controller function.
When a client connects to the server with ws://localhost:3001/chat like URL, Agentica made chatbot would be composed and Super AI cahtbot conversation will be started.
And following the guide of @WebSocketRoute document, build SDK (Software Development Kit) library for the client, so that complete the AI chatbot development.
Principles
Agent Strategy
When user says, @agentica/core delivers the conversation text to the selector agent, and let the selector agent to find (or cancel) candidate functions from the context. If the selector agent could not find any candidate function to call and there is not any candidate function previously selected either, the selector agent will work just like a plain ChatGPT.
And @agentica/core enters to a loop statement until the candidate functions to be empty. In the loop statement, caller agent tries to LLM function calling by analyzing the user’s conversation text. If context is enough to compose arguments of candidate functions, the caller agent actually calls the target functions, and let decriber agent to explain the function calling results. Otherwise the context is not enough to compose arguments, caller agent requests more information to user.
Such LLM (Large Language Model) function calling strategy separating selector, caller, and describer is the key logic of @agentica/core.
Validation Feedback
import { FunctionCall } from "pseudo";
import { ILlmFunction, IValidation } from "typia";
export const correctFunctionCall = (p: {
call: FunctionCall;
functions: Array<ILlmFunction<"chatgpt">>;
retry: (reason: string, errors?: IValidation.IError[]) => Promise<unknown>;
}): Promise<unknown> => {
// FIND FUNCTION
const func: ILlmFunction<"chatgpt"> | undefined =
p.functions.find((f) => f.name === p.call.name);
if (func === undefined) {
// never happened in my experience
return p.retry(
"Unable to find the matched function name. Try it again.",
);
}
// VALIDATE
const result: IValidation<unknown> = func.validate(p.call.arguments);
if (result.success === false) {
// 1st trial: 50% (gpt-4o-mini in shopping mall chatbot)
// 2nd trial with validation feedback: 99%
// 3nd trial with validation feedback again: never have failed
return p.retry(
"Type errors are detected. Correct it through validation errors",
{
errors: result.errors,
},
);
}
return result.data;
}Is LLM function calling perfect?
The answer is not, and LLM (Large Language Model) vendors like OpenAI take a lot of type level mistakes when composing the arguments of the target function to call. Even though an LLM function calling schema has defined an Array<string> type, LLM often fills it just by a string typed value.
Therefore, when developing an LLM function calling agent, the validation feedback process is essentially required. If LLM takes a type level mistake on arguments composition, the agent must feedback the most detailed validation errors, and let the LLM to retry the function calling referencing the validation errors.
About the validation feedback, @agentica/core is utilizing typia.validate<T>() and typia.llm.application<Class, Model>() functions. They construct validation logic by analyzing TypeScript source codes and types in the compilation level, so that detailed and accurate than any other validators like below.
Such validation feedback strategy and combination with typia runtime validator, @agentica/core has achieved the most ideal LLM function calling. In my experience, when using OpenAI’s gpt-4o-mini model, it tends to construct invalid function calling arguments at the first trial about 50% of the time. By the way, if correct it through validation feedback with typia, success rate soars to 99%. And I’ve never had a failure when trying validation feedback twice.
| Components | typia | TypeBox | ajv | io-ts | zod | C.V. |
|---|---|---|---|---|---|---|
| Easy to use | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Object (simple) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Object (hierarchical) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Object (recursive) | ✔ | ❌ | ✔ | ✔ | ✔ | ✔ |
| Object (union, implicit) | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Object (union, explicit) | ✔ | ✔ | ✔ | ✔ | ✔ | ❌ |
| Object (additional tags) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Object (template literal types) | ✔ | ✔ | ✔ | ❌ | ❌ | ❌ |
| Object (dynamic properties) | ✔ | ✔ | ✔ | ❌ | ❌ | ❌ |
| Array (rest tuple) | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Array (hierarchical) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Array (recursive) | ✔ | ✔ | ✔ | ✔ | ✔ | ❌ |
| Array (recursive, union) | ✔ | ✔ | ❌ | ✔ | ✔ | ❌ |
| Array (R+U, implicit) | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Array (repeated) | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Array (repeated, union) | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Ultimate Union Type | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
C.V.meansclass-validator
OpenAPI Specification
@agentica/core obtains LLM function calling schemas from both Swagger/OpenAPI documents and TypeScript class types. The TypeScript class type can be converted to LLM function calling schema by typia.llm.application<Class, Model>() function. Then how about OpenAPI document? How Swagger document can be LLM function calling schema.
The secret is in the above diagram.
In the OpenAPI specification, there are three versions with different definitions. And even in the same version, there are too much ambiguous and duplicated expressions. To resolve these problems, @samchon/openapi is transforming every OpenAPI documents to v3.1 emended specification. The @samchon/openapi’s emended v3.1 specification has removed every ambiguous and duplicated expressions for clarity.
With the v3.1 emended OpenAPI document, @samchon/openapi converts it to a migration schema that is near to the function structure. And as the last step, the migration schema will be transformed to a specific LLM vendor’s function calling schema. LLM function calling schemas are composed like this way.
Why do not directly convert, but intermediate?
If directly convert from each version of OpenAPI specification to specific LLM’s function calling schema, I have to make much more converters increased by cartesian product. In current models, number of converters would be 12 = 3 x 4.
However, if define intermediate schema, number of converters are shrunk to plus operation. In current models, I just need to develop only (7 = 3 + 4) converters, and this is the reason why I’ve defined intermediate specification. This way is economic.